

Job Postings Looking for GPT Skills Are Also Looking For...
Job Postings Looking for GPT Skills Are Also Looking For...
A Former Programmer Does Something Amazing with the GPT API


I’m a programmer. Well, I used to be. I was definitely a programmer 25 years ago. I don’t code much anymore beyond a little Apps Script in Google Sheets.
But I had an itch I wanted to scratch, and the OpenAI’s APIs seemed like a promising approach.
Correlated Technologies in Job Postings
For some time, I’ve wanted to know what technologies are correlated in job postings. For example, if a job posting wants HTML experience, it probably also wants CSS. But how would you discover these correlations?
This turns out to be a hard problem.
First, how do you even identify a “technology” in a job posting? One option is to have a list of technologies and search the job posting for every one. That will work for known technologies, but you would never discover new technologies with that methodology. Also, developing a list of every technology is non-trivial.
Prior to GPT, I was stuck.
Enter the OpenAI API
ChatGPT (technically the GPT-3.5-turbo model) is drop dead simple to program against. Here’s the python code:
import openai
openai.api_key = "[OPENAI API KEY]"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a bot that \
extracts technology names from job postings"},
{"role": "user", "content": "Look at the following \
job posting. If the job posting does not appear to \
be related to AI or machine learning, output just the \
word 'no'. Otherwise, output a semicolon separated list \
of technologies from the job posting.\n" + file_contents}
],
temperature=0.0
)
It’s basically one line of code. You call “openai.ChatCompletion.create”. You tell it which chat model you want to use, and then you give it a “system” prompt and a “user” prompt. The system prompt sets the context for the bot. The user prompt is what you would type into the ChatGPT web site.
The last parameter, temperature, controls the randomness in the model. I wanted the model to be 100% consistent. Feed the same job posting in, get the same results out. Setting the temperature to 0 does this.
Finally, “file_contents” is a string that contains the job posting. It’s not even clean. It’s just 100% of the text that shows up on a job posting web page. It has the menu bar, all the crap in the page footer, and a bunch of other noise in addition to the actual job posting. GPT-3.5 doesn’t care.
The First Piece of Magic
I used a loop to feed a couple hundred job postings through this section of code. I grabbed every job that mentioned GPT. However, GPT might mean “Global Procurement Team”, which isn’t a job I care about. So, the first thing the AI does is determine if the job has anything to do with AI. If not, it just outputs “no”.
Again, without an LLM, this would be hard. As in, I don’t know how to write code that reliably detects whether a job is AI related.
The Second Piece of Magic
Next, the prompt discerns and outputs all the technologies that are listed in the job posting. Feed a job posting in, get an output like:
BERT; BART; NLTK; Gensim; spaCy; TensorFlow; Pytorch; FastAPI; PostgreSQL; Kubernetes
Crazy.
There are whole businesses built on proprietary algorithms to parse resumes, job postings, contracts, receipts, etc. GPT-3.5 (not even the very latest model) can do all these things, and it wasn’t specifically designed to do any of them.
Such is the nature of AI. Newer general-purpose models out-perform older purpose-built models.
The Final Piece of Magic
I was pretty hopeful that I could just count up how many times a technology appeared, and be done. But of course not. Some job postings ask for experience with “NLP”, others ask for “Natural Language Processing”, and still other ask for “Natural Language Processing (NLP)”. This is the case with many technologies. (“Azure” in one, “Microsoft Azure” in another)
At this point I was impatient. I could have written code for this last part, but instead, I just pasted all the technologies into ChatGPT, told it to “merge any that mean the same thing and output each technology with a count of how many times it occurred”, each on its own line.
The result was something I could paste into a word cloud generator:
Tensorflow;16
PyTorch;16
GPT;16
Python;14
BERT;12
NLP;10
…
Conclusion
One model, three magic tricks. What I did with this simple python script would have probably won a Kaggle competition before GPT.
In review, as a mostly retired programmer who had to ask Google or ChatGPT for help on literally every line of code, I used AI to:
Determine which job postings are related to AI.
Extract technologies names from those job postings.
Combine and count technologies that are logically the same thing.
The code is easy. The problems it can solve are hard. The disruption will be immense.
P.S.
I focused on extracting technologies because it was hard, but with a tiny change to the prompt, you can extract anything. Like salary ranges per title. Here’s the output, styled by Excel:
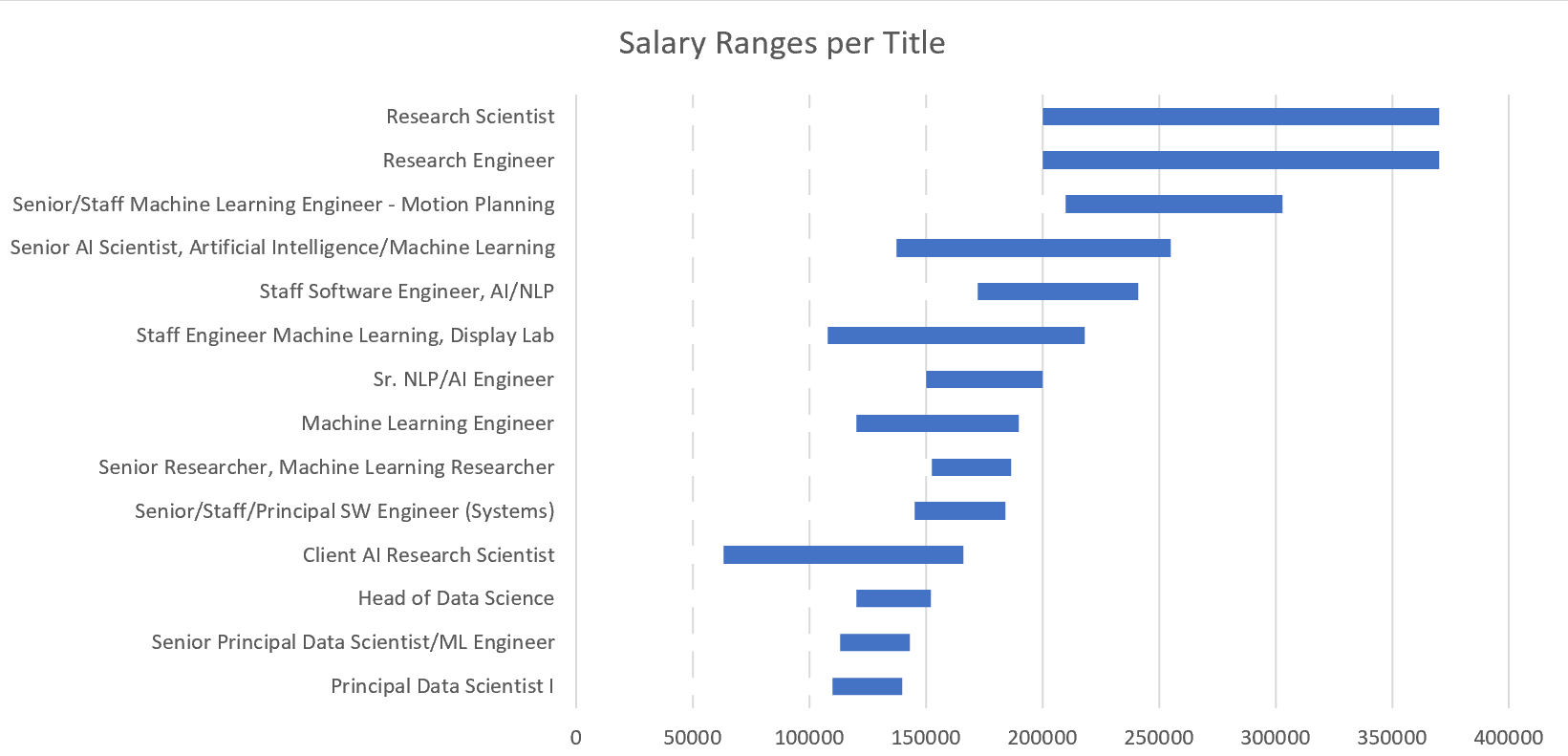
And here’s the prompt:
Look at the following job posting. If the job posting does not appear to be related to AI or machine learning, or the job posting doesn't list a salary, output the word 'no'. Otherwise, output in the following format [job title];[low salary];[high salary]. If the there is only one salary, output it for both low and high. Output the salaries as numbers, meaning 68k should be output as 68000.
P.P.S It Isn’t Free
All the testing, debugging, etc., cost me $1.01 in OpenAI API fees. I’m guessing the final “production run” was probably $0.10. Once the GPT-4 API is available, it’s supposed to be 1/10th the cost, so a production run would be $0.01. Still, at scale, it could add up.